VideoCube is a high-quality and large-scale benchmark to create a challenging real-world experimental environment for Global Instance Tracking (GIT). MGIT is a high-quality and multi-modal benchmark based on VideoCube-Tiny to fully represent the complex spatio-temporal and causal relationships coupled in longer narrative content. DTVLT is a new visual language tracking benchmark with diverse texts, based on five prominent VLT and SOT benchmarks, including three sub-tasks: short-term tracking, long-term tracking, and global instance tracking.
Task
Global Instance Tracking (GIT) task aims to model the fundamental visual function of humans for motion perception without any assumptions about camera or motion consistency.
Key Features
Large-Scale
VideoCube contains 500 video segments of real-world moving objects and over 7.4 million labeled bounding boxes. We guarantee that each video contains at least 4008 frames, and the average frame length in VideoCube is around 14920.
Multiple Collection Dimension
The collection of VideoCube is based on six dimensions to describe the spatio-temporal relationship and causal relationship of film narrative, which provides an extensive dataset for the novel GIT task.
Comprehensive Attribute Selection
VideoCube provides 12 attributes for each frame to reflect the challenging situations in actual applications, and implement a more elaborate reference for the performance analysis.
Scientific Evaluation
VideoCube provides classical metrics and novel metrics for to evaluation algorithms. Besides, this benchmark also provides human baseline to measure the intelligence level of existing methods.
Multi-granularity Semantic Annotation
MGIT design a hierarchical multi-granular semantic annotation strategy to provide scientific natural
language information. Video content is annotated by three grands (i.e., action, activity, and
story).
Evaluation Mechanism for Multi-modal Tracking
MGIT expand the evaluation mechanism by conducting experiments under both traditional evaluation
mechanisms (multi-modal single granularity, single visual modality) and evaluation mechanisms adapted to
MGIT (multi-modal multi-granularity).
Latest News
- [2025.11.8] Recently, we have proposed a new video reasoning benchmark, named CausalStep, The CausalStep paper has been accepted as Oral presentation by the 40th AAAI Conference on Artificial Intelligence (AAAI 2026, Oral)! The paper and the updated toolkit will be released soon.
- [2024.6.10] Recently, we have proposed a new visual language tracking benchmark with diverse texts, named DTVLT, based on five prominent VLT and SOT benchmarks, including three sub-tasks: short-term tracking, long-term tracking, and global instance tracking, aiming to support further research in VLT and video understanding. Now you can download the dataset from the download page via the URLs of DTVLT. We have updated the semantic labels in the OneDrive and Baiduyun Disk. The paper, experimental results, and toolkit about DTVLT will be updated gradually.
- [2024.4.18] Recently, we have proposed a new diverse text generation method for visual language tracking based on LLM, named DTLLM-VLT, The DTLLM-VLT paper has been accepted as Oral presentation and won the Best Paper Honorable Mention Award by the 3rd CVPR Workshop on Vision Datasets Understanding (CVPRW, Oral, Best Paper Honorable Mention Award)!
- [2024.1.21] The submission system and real-time leaderboard for MGIT (action, activity and story granularity) have been released!
- [2023.12.20] Recently, we have proposed a bionic drone-based single object tracking benchmark named BioDrone for robust vision research. Now you can download the dataset from the download page via the URL. The BioDrone paper has been accepted by International Journal of Computer Vision (IJCV)!
- [2023.12.19] The toolkit has been updated to support MGIT.
- [2023.09.22] The MGIT paper has been accepted by the 37th Conference on Neural Information Processing Systems (NeurIPS 2023) Track on Datasets and Benchmark! The paper and the updated toolkit will be released soon.
- [2023.09.12] The SOTVerse paper has been accepted by International Journal of Computer Vision (IJCV)!
- [2023.06.13] Recently, we have proposed a new multi-modal global instance tracking benchmark named MGIT. It consists of 150 long video sequences with a total of 2.03 million frames, aiming to fully represent the complex spatio-temporal and casual relationships coupled in longer narrative content. Now you can download the dataset from the download page via the URLs of VideoCube-Tiny (the 150 sequences in MGIT are the same as those in VideoCube-Tiny, but with additional semantic information). We have updated the semantic labels in the OneDrive and Baiduyun Disk. The paper, experimental results, and toolkit about MGIT will be updated gradually.
- [2023.02.10] To make it easier for users to research with VideoCube, we have selected 150 representative sequences from the original version (500 sequences) to form VideoCube-Tiny. The original full version includes 500 sequences (1.4T), while the tiny version includes 150 sequences (344G, 105 sequences in train-set, 15 sequences in val-set, and 30 sequences in test-set). The download page, leaderboard in OPE and R-OPE mechanisms, and the toolkit have also been updated. You are encouraged to report the results of VideoCube-Tiny in your research works.
- [2022.04.18] We have released SOTVerse, a user-defined task space of single object tracking, and the related paper has been released on arXiv.
- [2022.03.04] We have updated the download page, submit instructions, and leaderboard in OPE and R-OPE mechanisms.
- [2022.02.26] The GIT paper has been accepted by IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)!
- [2021.11.21] The videocube-toolkit has been released!
- [2021.11.17] The submission system and real-time leaderboard have been released!
- [2021.06.07] The download links and the register system have been released!
- [2021.05.24] The home page and the instructions page have been released!
Publications

Please cite our IEEE TPAMI paper if VideoCube helps your research.

Please cite our NeurIPS paper if MGIT helps your research.
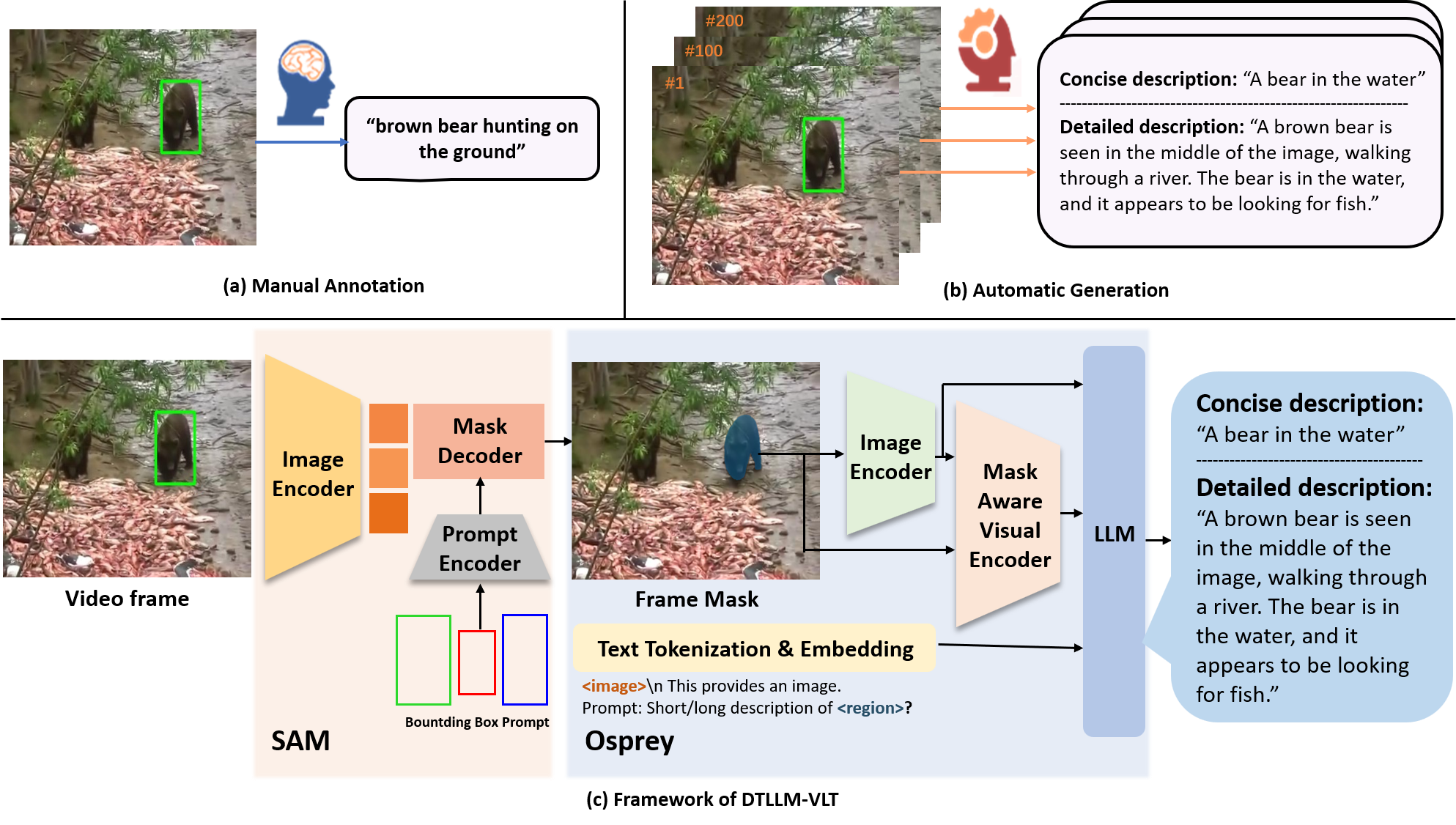
Please cite our CVPRW paper if DTLLM-VLT helps your research.
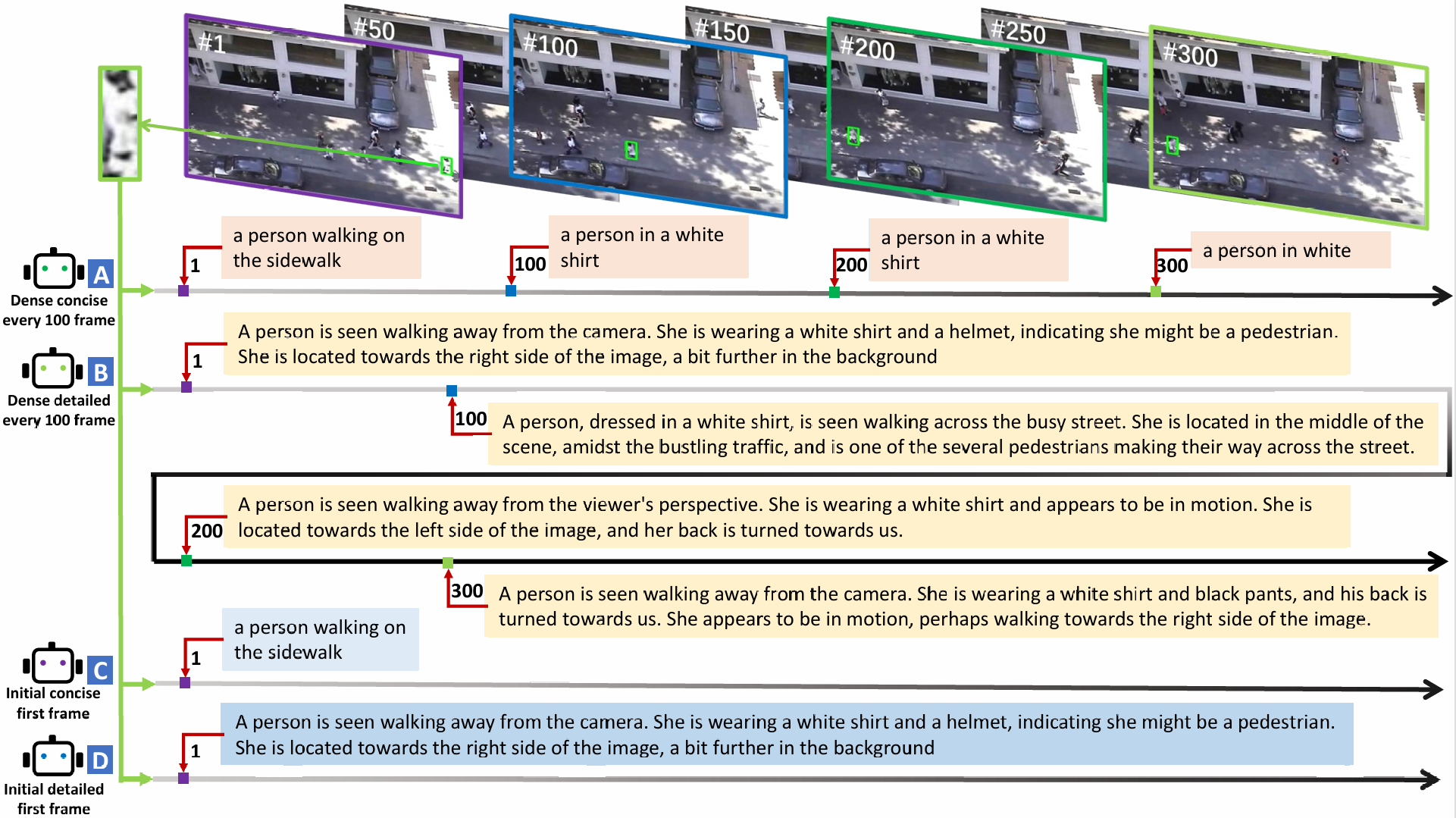
Please cite our paper if DTVLT helps your research.

Please cite our paper if VLT-MI helps your research.
Demo
VideoCube Benchmark
MGIT Benchmark
Organizers
- Shiyu Hu, Center for Research on Intelligent System and Engineering (CRISE), CASIA.
- Xuchen Li, Center for Research on Intelligent System and Engineering (CRISE), CASIA.
- Xin Zhao, Center for Research on Intelligent System and Engineering (CRISE), CASIA.
- Lianghua Huang, Center for Research on Intelligent System and Engineering (CRISE), CASIA.
- Kaiqi Huang, Center for Research on Intelligent System and Engineering (CRISE), CASIA.
Maintainer
- Xuchen Li, Center for Research on Intelligent System and Engineering (CRISE), CASIA.
Contact
Please contact us if you have any problems or suggestions.