DTVLT Benchmark: Dataset
We propose a new visual language tracking benchmark with diverse texts, named DTVLT, based on five prominent VLT and SOT benchmarks, including three sub-tasks: short-term tracking, long-term tracking, and global instance tracking.
DTVLT Benchmark: Generation Tool
Multi-granularity semantic generation method
Traditional datasets for VLT are dependent on manual annotations. This process is costly, operates at a single annotation granularity, and is not suitable for annotating large volumes of data. To overcome these challenges, we have developed DTLLM-VLT, a method capable of producing extensive and diverse text generation based on LLM. The pipeline of text generation for DTVLT is illustrated below. By taking video frames and the BBox of objects as inputs, DTLLM-VLT generates concise and detailed descriptions for the relevant objects. This methodology enables us to generate large-scale, diverse granularities text at low costs.

DTVLT Benchmark: Generation Strategy
Multi-granularity semantic generation strategy
Initial and dense text descriptions
Inspired by the text annotations approach in OTB99_Lang and TNL2K, we generate text for the first frame of each video. Additionally, recognizing that 4 seconds is the threshold between human instant memory and short-term memory, we prepare for the most challenging scenario where the algorithm may not have an efficient memory mechanism. Therefore, at a frame rate of 25 FPS, equating to every 100 frames in 4 seconds, we provide the algorithm with generated text. We believe that this frequency of updates optimally maintains the algorithm's memory state and improves tracking capabilities.
Concise and detailed text descriptions.
For the algorithm, if the BBox already adequately captures the temporal and spatial dynamics of the object, the texts should concentrate on delivering key semantic elements such as the object's category and location. When the BBox does not provide enough information for the tracker's efficient learning, more comprehensive texts are required to make up for the absent temporal and spatial connections. As a result, we generate two types of textual descriptions: concise and detailed. The concise text conveys essential information about the object, like its category (bear) and position (in the water), whereas the detailed text encompasses further spatio-temporal specifics such as color, relative position, and activities.

DTVLT Benchmark: Generation Analysis
Multi-granularity semantic generation analysis
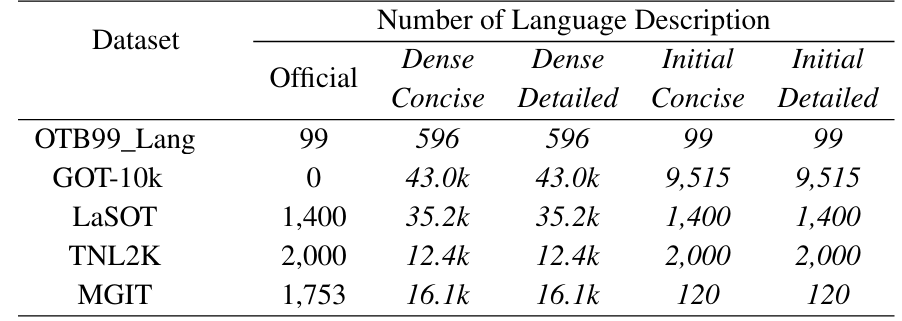
We generate text descriptions for the DTVLT using the DTLLM-VLT, which includes 26.4k initial descriptions (divided equally between 13.2k concise and 13.2k detailed texts) and 214.6k dense descriptions (also equally divided into 107.3k concise and 107.3k detailed texts). The quantity of our dense texts is 45.9 times larger than the official annotations. Additional information on the number of semantic descriptions is available in Table~\ref{vldataset}. These semantic descriptions consist of 2.5 million words, featuring 17.6k non-repetitive words.

DTVLT Benchmark: Evaluation mechanism
To fairly compare the tracking performance on five datasets, (A) we directly use the officially provided weights to test with the official annotations and on the DTVLT. (B) We retrain these models for 50 epochs on the basis of the official weights using DTVLT and test under the corresponding settings to evaluate Area Under the Curve (AUC), and tracking precision (P).
